Abstract
Supervised learning can be viewed as distilling relevant information from input data into feature representations.
This process becomes difficult when supervision is noisy as the distilled information might not be relevant.
In fact, recent research shows that networks can easily overfit all labels including those that are corrupted, and hence can hardly generalize to clean datasets.
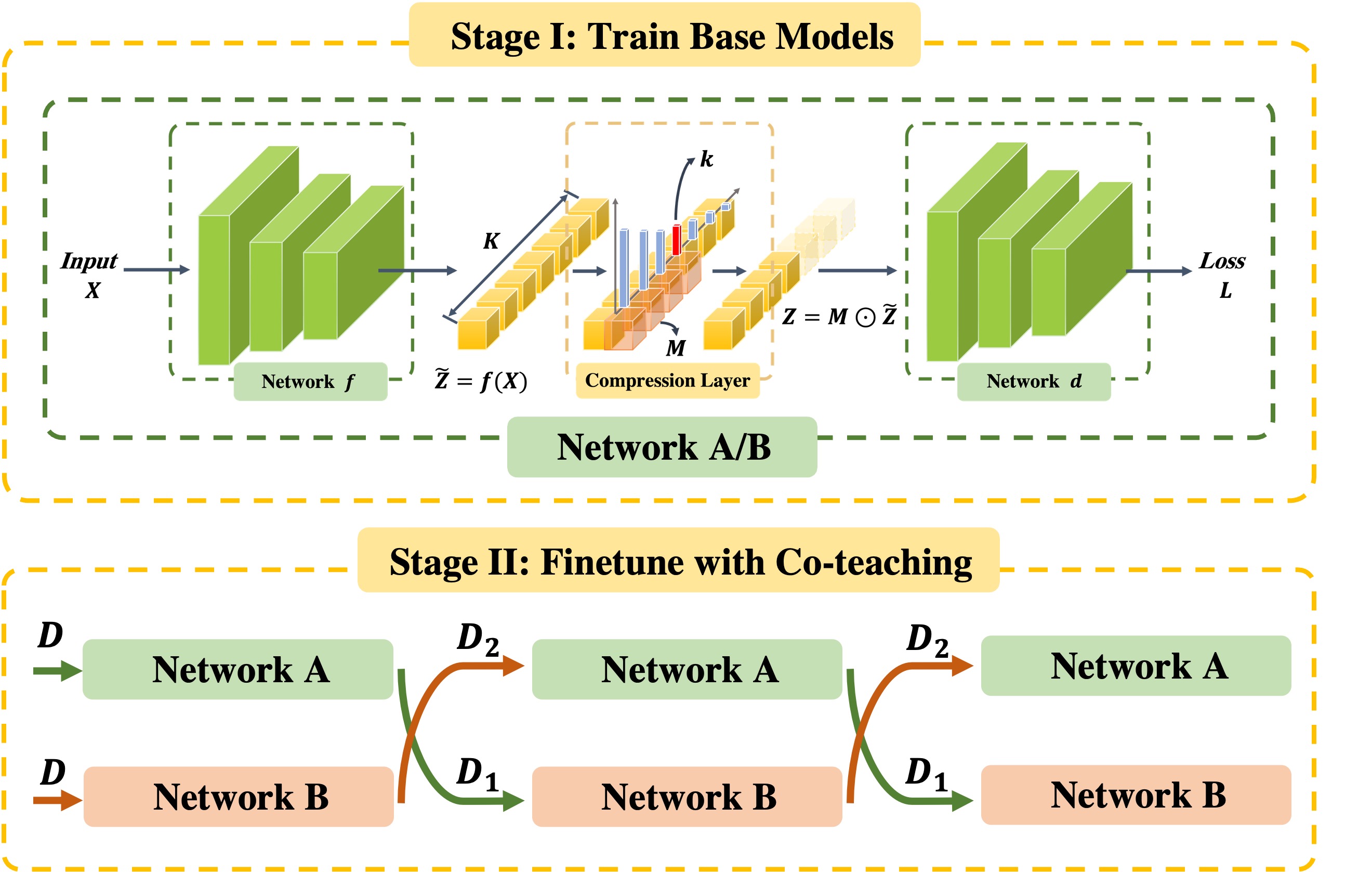
In this paper, we focus on the problem of learning with noisy labels and introduce compression inductive bias to network architectures to alleviate this over-fitting problem.
More precisely, we revisit one classical regularization named Dropout
and its variant Nested Dropout.
Dropout can serve as a compression constraint for its feature dropping mechanism,
while Nested Dropout further learns ordered feature representations w.r.t. feature importance.
Moreover, the trained models with compression regularization are further combined with Co-teaching for performance boost.
Theoretically, we conduct bias-variance decomposition of the objective function under compression regularization.
We analyze it for both single model and Co-teaching.
This decomposition provides three insights:
(i) it shows that over-fitting is indeed an issue in learning with noisy labels;
(ii) through an information bottleneck formulation, it explains why the proposed feature compression helps in combating label noise;
(iii) it gives explanations on the performance boost brought by incorporating compression regularization into Co-teaching.
Experiments show that our simple approach can have comparable or even better performance than the state-of-the-art methods on benchmarks with real-world label noise including Clothing1M and ANIMAL-10N.
Method
Results
Please refer to our paper for more experiments.
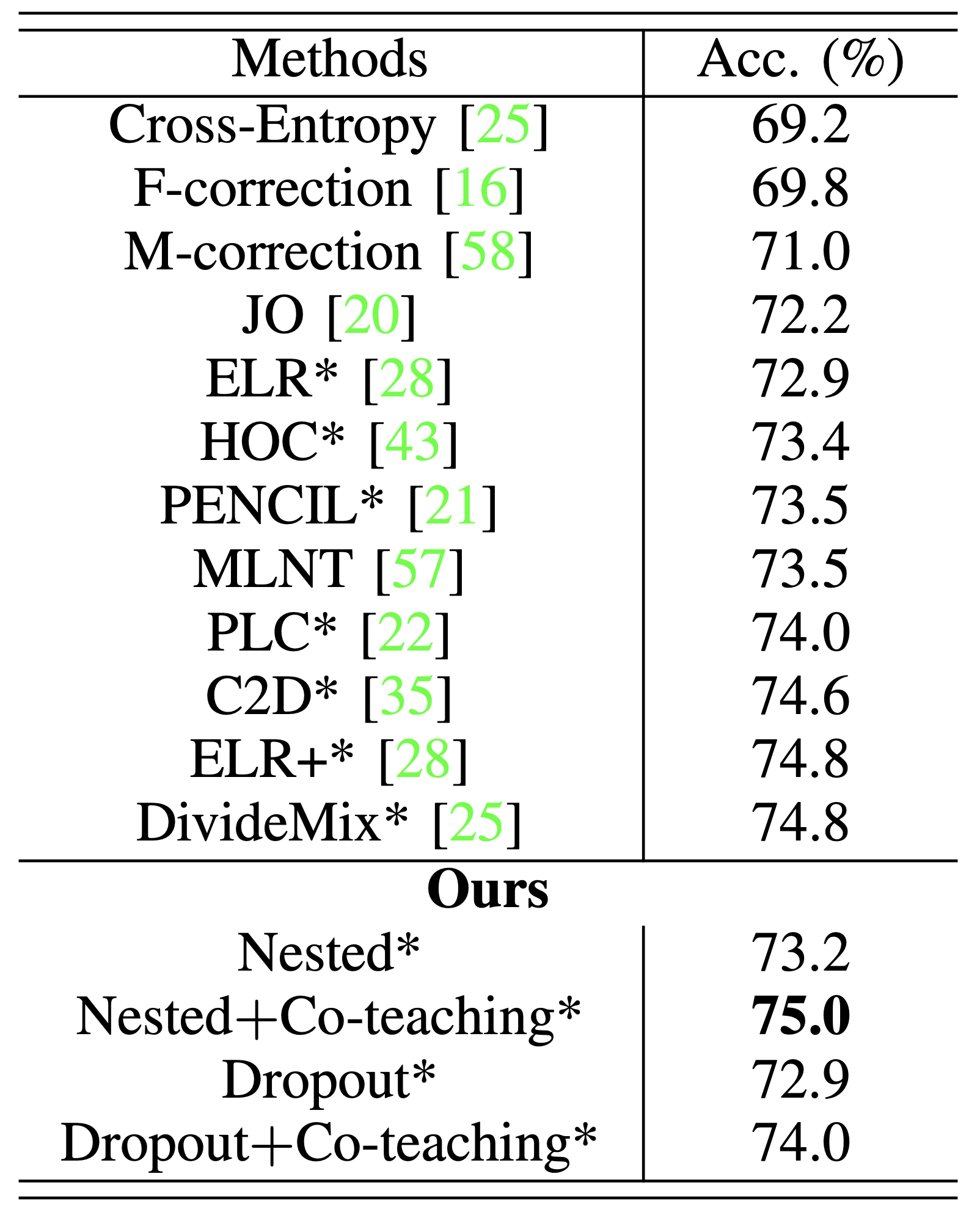
Clothing1M with real-world label noise
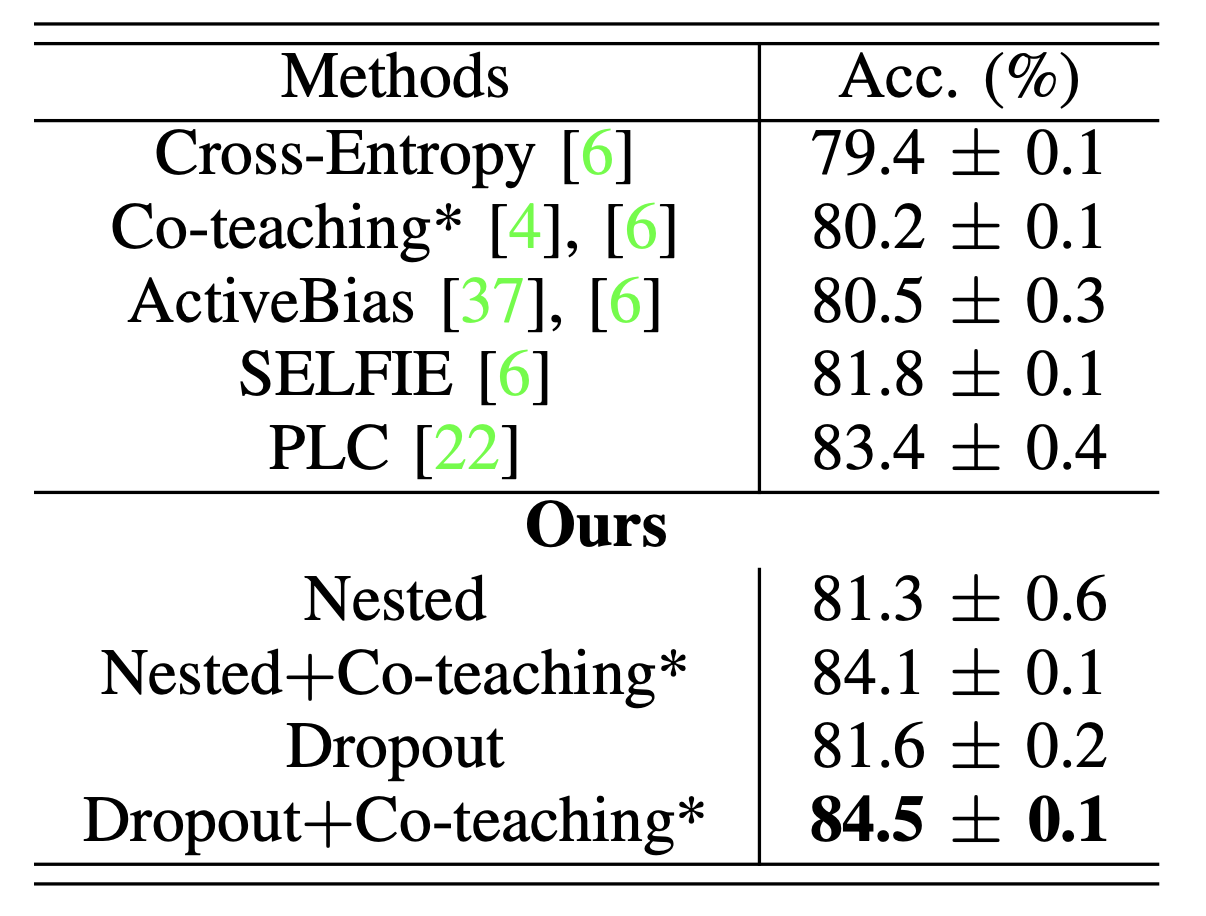
ANIMAL-10N with real-world label noise
Test accuracy (%) of state-of-the-art methods on Clothing1M (noise ratio ∼38%).
All approaches are implemented with ResNet-50 architecture.
Results with ``*" use a balanced subset or a balanced loss.
Average test accuracy (%) with standard deviation (3 runs) of state-of-the-art methods on ANIMAL-10N (noise ratio ~8%).
All approaches are implemented with VGG-19 architecture.
Results with ``*" use two networks for training.
Resources
Paper

Code
Workshop Paper

BibTeX
If you find this work useful for your research, please cite:
@ARTICLE{chen2022compressing,
author={Chen, Yingyi and Hu, Shell Xu and Shen, Xi and Ai, Chunrong and Suykens, Johan A. K.},
journal={IEEE Transactions on Neural Networks and Learning Systems},
title={Compressing Features for Learning with Noisy Labels},
year={2022}
}
Acknowledgements
We appreciate Qinghua Tao for helpful comments and discussions.
This work is jointly supported by EU: The research leading to these results has received funding from the European Research Council under the European Union's Horizon 2020 research and innovation program / ERC Advanced Grant E-DUALITY (787960). This paper reflects only the authors' views and the Union is not liable for any use that may be made of the contained information.
Research Council KU Leuven:
Optimization frameworks for deep kernel machines C14/18/068
Flemish Government:
FWO: projects: GOA4917N (Deep Restricted Kernel Machines: Methods and Foundations), PhD/Postdoc grant
This research received funding from the Flemish Government (AI Research Program).
EU H2020 ICT-48 Network TAILOR (Foundations of Trustworthy AI - Integrating Reasoning, Learning and Optimization)
Leuven.AI Institute